Глава 11: Постановка целей и мониторинг
Для того чтобы AI агенты были по-настоящему эффективными и целенаправленными, им нужно больше, чем просто способность обрабатывать информацию или использовать инструменты; им необходимо четкое понимание направления и способ узнать, действительно ли они достигают успеха. Именно здесь вступает в игру шаблон постановки целей и мониторинга. Он заключается в предоставлении агентам конкретных задач для работы и оснащении их средствами для отслеживания прогресса и определения того, достигнуты ли эти задачи.
Обзор шаблона постановки целей и мониторинга
Подумайте о планировании поездки. Вы не просто спонтанно появляетесь в пункте назначения. Вы решаете, куда хотите поехать (целевое состояние), выясняете, откуда начинаете (исходное состояние), рассматриваете доступные варианты (транспорт, маршруты, бюджет), а затем составляете последовательность шагов: бронируете билеты, упаковываете сумки, добираетесь до аэропорта/вокзала, садитесь на транспорт, прибываете, находите жилье и так далее. Этот пошаговый процесс, часто учитывающий зависимости и ограничения, является основой того, что мы понимаем под планированием в агентных системах.
В контексте AI агентов планирование обычно включает в себя принятие агентом высокоуровневой задачи и автономное или полуавтономное создание серии промежуточных шагов или подцелей. Эти шаги затем могут выполняться последовательно или в более сложном потоке, потенциально включающем другие шаблоны, такие как использование инструментов, маршрутизация или многоагентное сотрудничество. Механизм планирования может включать сложные алгоритмы поиска, логические рассуждения или, все чаще, использование возможностей больших языковых моделей (LLM) для генерации правдоподобных и эффективных планов на основе их обучающих данных и понимания задач.
Хорошие возможности планирования позволяют агентам решать проблемы, которые не являются простыми одношаговыми запросами. Это позволяет им обрабатывать многогранные запросы, адаптироваться к изменяющимся обстоятельствам путем перепланирования и организовывать сложные рабочие процессы. Это основополагающий шаблон, который лежит в основе многих продвинутых агентных поведений, превращая простую реактивную систему в систему, которая может проактивно работать над достижением определенной цели.
Практические применения и случаи использования
Шаблон постановки целей и мониторинга необходим для создания агентов, которые могут работать автономно и надежно в сложных сценариях реального мира. Вот несколько практических применений:
Автоматизация клиентской поддержки: Цель агента может заключаться в "решении запроса клиента по биллингу". Он отслеживает разговор, проверяет записи в базе данных и использует инструменты для корректировки биллинга. Успех отслеживается путем подтверждения изменения биллинга и получения положительной обратной связи от клиента. Если проблема не решена, происходит эскалация.
Персонализированные системы обучения: Обучающий агент может иметь цель "улучшить понимание алгебры учащимися". Он отслеживает прогресс учащегося в упражнениях, адаптирует учебные материалы и отслеживает показатели производительности, такие как точность и время выполнения, корректируя свой подход, если учащийся испытывает трудности.
Помощники по управлению проектами: Агенту может быть поставлена задача "обеспечить завершение вехи проекта X к дате Y". Он отслеживает статусы задач, коммуникации команды и доступность ресурсов, отмечая задержки и предлагая корректирующие действия, если цель находится под угрозой.
Автоматизированные торговые боты: Цель торгового агента может заключаться в "максимизации прибыли портфеля при соблюдении толерантности к риску". Он постоянно отслеживает рыночные данные, текущую стоимость портфеля и индикаторы риска, выполняя сделки, когда условия соответствуют его целям, и корректируя стратегию при превышении пороговых значений риска.
Робототехника и автономные транспортные средства: Основная цель автономного транспортного средства - "безопасно перевезти пассажиров из точки А в точку Б". Оно постоянно отслеживает окружающую среду (другие транспортные средства, пешеходов, дорожные знаки), свое собственное состояние (скорость, топливо) и прогресс по запланированному маршруту, адаптируя свое поведение вождения для безопасного и эффективного достижения цели.
Модерация контента: Цель агента может заключаться в "выявлении и удалении вредоносного контента с платформы X". Он отслеживает входящий контент, применяет модели классификации и отслеживает метрики, такие как ложноположительные/ложноотрицательные результаты, корректируя критерии фильтрации или эскалируя неоднозначные случаи к человеческим модераторам.
Этот шаблон является основополагающим для агентов, которые должны работать надежно, достигать конкретных результатов и адаптироваться к динамическим условиям, обеспечивая необходимую основу для интеллектуального самоуправления.
Практический пример кода
Для иллюстрации шаблона постановки целей и мониторинга у нас есть пример с использованием LangChain и OpenAI APIs. Этот Python скрипт описывает автономного AI агента, созданного для генерации и усовершенствования Python кода. Его основная функция - создание решений для указанных проблем, обеспечивая соответствие определенным пользователем стандартам качества.
Он использует шаблон "постановки целей и мониторинга", где он не просто генерирует код один раз, а входит в итеративный цикл создания, самооценки и улучшения. Успех агента измеряется его собственной AI-оценкой того, успешно ли сгенерированный код соответствует первоначальным задачам. Конечным результатом является отшлифованный, прокомментированный и готовый к использованию Python файл, который представляет кульминацию этого процесса усовершенствования.
Зависимости:
pip install langchain_openai openai python-dotenv
# .env файл с ключом в OPENAI_API_KEYВы можете лучше понять этот скрипт, представив его как автономного AI программиста, назначенного на проект (см. Рис. 1). Процесс начинается, когда вы передаете AI подробное техническое задание проекта, которое является конкретной проблемой программирования, которую ему нужно решить.
# MIT License
# Copyright (c) 2025 Mahtab Syed
# https://www.linkedin.com/in/mahtabsyed/
"""
Hands-On Code Example - Iteration 2
- To illustrate the Goal Setting and Monitoring pattern, we have an example using LangChain and OpenAI APIs:
Objective: Build an AI Agent which can write code for a specified use case based on specified goals:
- Accepts a coding problem (use case) in code or can be as input.
- Accepts a list of goals (e.g., "simple", "tested", "handles edge cases") in code or can be input.
- Uses an LLM (like GPT-4o) to generate and refine Python code until the goals are met. (I am using max 5 iterations, this could be based on a set goal as well)
- To check if we have met our goals I am asking the LLM to judge this and answer just True or False which makes it easier to stop the iterations.
- Saves the final code in a .py file with a clean filename and a header comment.
"""
import os
import random
import re
from pathlib import Path
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
# 🔒 Load environment variables
_ = load_dotenv(find_dotenv())
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise EnvironmentError("❌ Please set the OPENAI_API_KEY environment variable.")
# ✅ Initialize OpenAI model
print("📡 Initializing OpenAI LLM (gpt-4o)...")
llm = ChatOpenAI(
model="gpt-4o", # If you dont have access to got-4o use other OpenAI LLMs
temperature=0.3,
openai_api_key=OPENAI_API_KEY,
)
# --- Utility Functions ---
def generate_prompt(
use_case: str, goals: list[str], previous_code: str = "", feedback: str = ""
) -> str:
print("📝 Constructing prompt for code generation...")
base_prompt = f"""
You are an AI coding agent. Your job is to write Python code based on the following use case:
Use Case: {use_case}
Your goals are:
{chr(10).join(f"- {g.strip()}" for g in goals)}
"""
if previous_code:
print("🔄 Adding previous code to the prompt for refinement.")
base_prompt += f"\nPreviously generated code:\n{previous_code}"
if feedback:
print("📋 Including feedback for revision.")
base_prompt += f"\nFeedback on previous version:\n{feedback}\n"
base_prompt += "\nPlease return only the revised Python code. Do not include comments or explanations outside the code."
return base_prompt
def get_code_feedback(code: str, goals: list[str]) -> str:
print("🔍 Evaluating code against the goals...")
feedback_prompt = f"""
You are a Python code reviewer. A code snippet is shown below. Based on the following goals:
{chr(10).join(f"- {g.strip()}" for g in goals)}
Please critique this code and identify if the goals are met. Mention if improvements are needed for clarity, simplicity, correctness, edge case handling, or test coverage.
Code:
{code}
"""
return llm.invoke(feedback_prompt)
def goals_met(feedback_text: str, goals: list[str]) -> bool:
"""
Uses the LLM to evaluate whether the goals have been met based on the feedback text.
Returns True or False (parsed from LLM output).
"""
review_prompt = f"""
You are an AI reviewer.
Here are the goals:
{chr(10).join(f"- {g.strip()}" for g in goals)}
Here is the feedback on the code:
\"\"\"
{feedback_text}
\"\"\"
Based on the feedback above, have the goals been met?
Respond with only one word: True or False.
"""
response = llm.invoke(review_prompt).content.strip().lower()
return response == "true"
def clean_code_block(code: str) -> str:
lines = code.strip().splitlines()
if lines and lines[0].strip().startswith("```"):
lines = lines[1:]
if lines and lines[-1].strip() == "```":
lines = lines[:-1]
return "\n".join(lines).strip()
def add_comment_header(code: str, use_case: str) -> str:
comment = f"# This Python program implements the following use case:\n# {use_case.strip()}\n"
return comment + "\n" + code
def to_snake_case(text: str) -> str:
text = re.sub(r"[^a-zA-Z0-9 ]", "", text)
return re.sub(r"\s+", "_", text.strip().lower())
def save_code_to_file(code: str, use_case: str) -> str:
print("💾 Saving final code to file...")
summary_prompt = (
f"Summarize the following use case into a single lowercase word or phrase, "
f"no more than 10 characters, suitable for a Python filename:\n\n{use_case}"
)
raw_summary = llm.invoke(summary_prompt).content.strip()
short_name = re.sub(r"[^a-zA-Z0-9_]", "", raw_summary.replace(" ", "_").lower())[:10]
random_suffix = str(random.randint(1000, 9999))
filename = f"{short_name}_{random_suffix}.py"
filepath = Path.cwd() / filename
with open(filepath, "w") as f:
f.write(code)
print(f"✅ Code saved to: {filepath}")
return str(filepath)
# --- Main Agent Function ---
def run_code_agent(use_case: str, goals_input: str, max_iterations: int = 5) -> str:
goals = [g.strip() for g in goals_input.split(",")]
print(f"\n🎯 Use Case: {use_case}")
print("🎯 Goals:")
for g in goals:
print(f" - {g}")
previous_code = ""
feedback = ""
for i in range(max_iterations):
print(f"\n=== 🔁 Iteration {i + 1} of {max_iterations} ===")
prompt = generate_prompt(use_case, goals, previous_code, feedback if isinstance(feedback, str) else feedback.content)
print("🚧 Generating code...")
code_response = llm.invoke(prompt)
raw_code = code_response.content.strip()
code = clean_code_block(raw_code)
print("\n🦾 Generated Code:\n" + "-" * 50 + f"\n{code}\n" + "-" * 50)
print("\n📤 Submitting code for feedback review...")
feedback = get_code_feedback(code, goals)
feedback_text = feedback.content.strip()
print("\n📥 Feedback Received:\n" + "-" * 50 + f"\n{feedback_text}\n" + "-" * 50)
if goals_met(feedback_text, goals):
print("✅ LLM confirms goals are met. Stopping iteration.")
break
print("🛠️ Goals not fully met. Preparing for next iteration...")
previous_code = code
final_code = add_comment_header(code, use_case)
return save_code_to_file(final_code, use_case)
# --- CLI Test Run ---
if __name__ == "__main__":
print("\n🤖 Welcome to the AI Code Generation Agent")
# Example 1
use_case_input = "Write code to find BinaryGap of a given positive integer"
goals_input = "Code simple to understand, Functionally correct, Handles comprehensive edge cases, Takes positive integer input only, prints the results with few examples"
run_code_agent(use_case_input, goals_input)
# Example 2
# use_case_input = "Write code to count the number of files in current directory and all its nested sub directories, and print the total count"
# goals_input = (
# "Code simple to understand, Functionally correct, Handles comprehensive edge cases, Ignore recommendations for performance, Ignore recommendations for test suite use like unittest or pytest"
# )
# run_code_agent(use_case_input, goals_input)
# Example 3
# use_case_input = "Write code which takes a command line input of a word doc or docx file and opens it and counts the number of words, and characters in it and prints all"
# goals_input = "Code simple to understand, Functionally correct, Handles edge cases"
# run_code_agent(use_case_input, goals_input)Вместе с этим заданием вы предоставляете строгий чек-лист качества, который представляет задачи, которые должен выполнить финальный код — критерии вроде "решение должно быть простым", "оно должно быть функционально корректным" или "оно должно обрабатывать неожиданные граничные случаи".
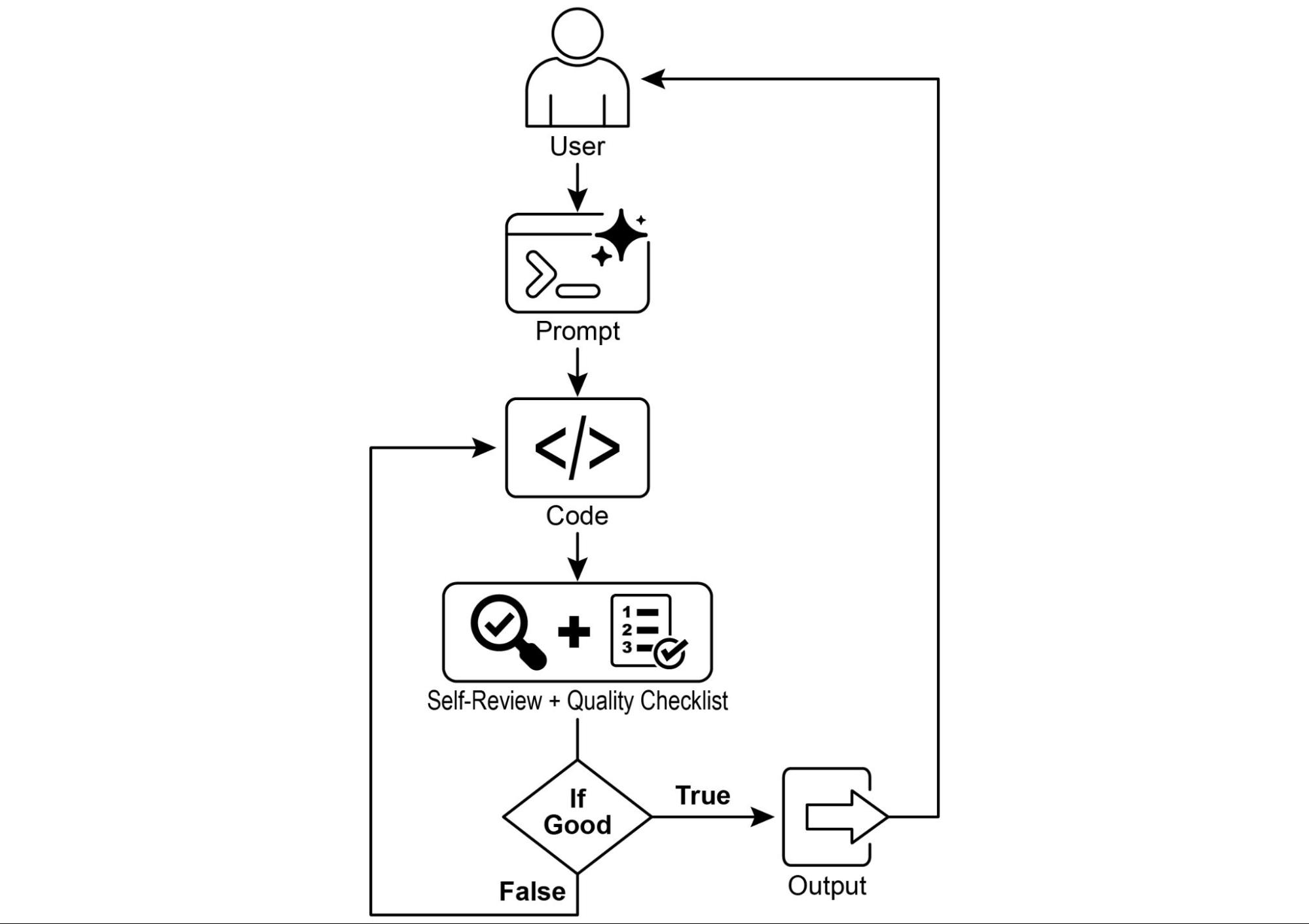
Рис.1: Пример постановки целей и мониторинга
Получив это задание, AI программист приступает к работе и создает свой первый черновик кода. Однако вместо того чтобы сразу же представить эту первоначальную версию, он останавливается для выполнения важного шага: тщательной самопроверки. Он скрупулезно сравнивает свое собственное творение с каждым пунктом чек-листа качества, который вы предоставили, действуя как собственный инспектор по обеспечению качества. После этой проверки он выносит простой, непредвзятый вердикт о своем прогрессе: "True", если работа соответствует всем стандартам, или "False", если она не дотягивает.
Если вердикт "False", AI не сдается. Он входит в фазу вдумчивой ревизии, используя выводы из своей самокритики для выявления слабых мест и интеллектуального переписывания кода. Этот цикл составления черновика, самопроверки и усовершенствования продолжается, с каждой итерацией стремясь приблизиться к целям. Этот процесс повторяется до тех пор, пока AI наконец не достигнет статуса "True", удовлетворив каждому требованию, или пока не достигнет предопределенного лимита попыток, подобно разработчику, работающему в условиях дедлайна. Как только код проходит эту финальную проверку, скрипт упаковывает отшлифованное решение, добавляя полезные комментарии и сохраняя его в чистый новый Python файл, готовый к использованию.
Предостережения и соображения: Важно отметить, что это иллюстративный пример, а не готовый к производству код. Для реальных приложений необходимо учитывать несколько факторов. LLM может не полностью понять предполагаемое значение цели и может неправильно оценить свою производительность как успешную. Даже если цель хорошо понята, модель может галлюцинировать. Когда одна и та же LLM отвечает как за написание кода, так и за оценку его качества, ей может быть сложнее обнаружить, что она идет в неправильном направлении.
В конечном счете, LLM не создают безупречный код по волшебству; вам все равно нужно запускать и тестировать созданный код. Кроме того, "мониторинг" в простом примере является базовым и создает потенциальный риск бесконечного выполнения процесса.
Act as an expert code reviewer with a deep commitment to producing clean, correct, and simple code. Your core mission is to eliminate code "hallucinations" by ensuring every suggestion is grounded in reality and best practices.
When I provide you with a code snippet, I want you to:
-- Identify and Correct Errors: Point out any logical flaws, bugs, or potential runtime errors.
-- Simplify and Refactor: Suggest changes that make the code more readable, efficient, and maintainable without sacrificing correctness.
-- Provide Clear Explanations: For every suggested change, explain why it is an improvement, referencing principles of clean code, performance, or security.
-- Offer Corrected Code: Show the "before" and "after" of your suggested changes so the improvement is clear.
Your feedback should be direct, constructive, and always aimed at improving the quality of the code.Более надежный подход включает разделение этих задач, назначив конкретные роли команде агентов. Например, я создал личную команду AI агентов, используя Gemini, где каждый имеет конкретную роль:
- Программист-коллега: Помогает писать код и проводить мозговые штурмы.
- Ревизор кода: Выявляет ошибки и предлагает улучшения.
- Документатор: Создает ясную и краткую документацию.
- Автор тестов: Создает всесторонние модульные тесты.
- Улучшатель промптов: Оптимизирует взаимодействие с AI.
В этой многоагентной системе ревизор кода, действуя как отдельная сущность от агента-программиста, имеет промпт, похожий на судью в примере, что значительно улучшает объективную оценку. Эта структура естественным образом ведет к лучшим практикам, поскольку агент-автор тестов может выполнить необходимость написания модульных тестов для кода, созданного программистом-коллегой.
Я оставляю заинтересованному читателю задачу добавления этих более сложных элементов управления и приближения кода к готовому к производству.
На первый взгляд
Что: AI агентам часто не хватает четкого направления, что не позволяет им действовать целенаправленно за пределами простых реактивных задач. Без определенных задач они не могут самостоятельно решать сложные многошаговые проблемы или организовывать сложные рабочие процессы. Более того, у них нет встроенного механизма для определения того, ведут ли их действия к успешному результату. Это ограничивает их автономию и не позволяет им быть по-настоящему эффективными в динамичных сценариях реального мира, где простого выполнения задач недостаточно.
Почему: Шаблон постановки целей и мониторинга предоставляет стандартизированное решение, встраивая чувство цели и самооценки в агентные системы. Он включает явное определение четких, измеримых задач для достижения агентом. Одновременно он устанавливает механизм мониторинга, который непрерывно отслеживает прогресс агента и состояние его окружения относительно этих целей. Это создает важную петлю обратной связи, позволяющую агенту оценивать свою производительность, корректировать курс и адаптировать план, если он отклоняется от пути к успеху. Внедряя этот шаблон, разработчики могут превратить простые реактивные агенты в проактивные, целенаправленные системы, способные к автономной и надежной работе.
Правило большого пальца: Используйте этот шаблон, когда AI агент должен автономно выполнять многошаговую задачу, адаптироваться к динамическим условиям и надежно достигать конкретной высокоуровневой цели без постоянного вмешательства человека.
Визуальное резюме:
Рис.2: Шаблоны целевого проектирования
Ключевые выводы
Ключевые выводы включают:
- Постановка целей и мониторинг оснащают агентов целью и механизмами для отслеживания прогресса.
- Цели должны быть конкретными, измеримыми, достижимыми, релевантными и ограниченными по времени (SMART).
- Четкое определение метрик и критериев успеха является важным для эффективного мониторинга.
- Мониторинг включает наблюдение за действиями агента, состояниями окружения и выводами инструментов.
- Петли обратной связи от мониторинга позволяют агентам адаптироваться, пересматривать планы или эскалировать проблемы.
- В Google ADK цели часто передаются через инструкции агента, а мониторинг осуществляется через управление состоянием и взаимодействие с инструментами.
Заключение
Эта глава сосредоточилась на критически важной парадигме постановки целей и мониторинга. Я подчеркнул, как эта концепция превращает AI агентов из просто реактивных систем в проактивные, целенаправленные сущности. Текст подчеркнул важность определения четких, измеримых задач и установления строгих процедур мониторинга для отслеживания прогресса. Практические применения продемонстрировали, как эта парадигма поддерживает надежную автономную работу в различных областях, включая клиентское обслуживание и робототехнику. Концептуальный пример кода иллюстрирует реализацию этих принципов в структурированной среде, используя директивы агента и управление состоянием для руководства и оценки достижения агентом его определенных целей. В конечном счете, оснащение агентов способностью формулировать и контролировать цели является фундаментальным шагом к созданию по-настоящему интеллектуальных и ответственных AI систем.
Ссылки
Навигация
Назад: [Глава 10. Протокол контекста модели](../../Часть 2/Глава 10. Протокол контекста модели.md)
Вперед: Глава 12. Обработка исключений и восстановление